Добавление новых букв в алфавит ДНК удваивает плотность хранения данных


ДНК естественным
образом состоит из комбинаций четырех азотистых оснований: аденина, гуанина,
цитозина и тимина. Обозначенные буквами A, G, C и T, эти основания группируются
в различных последовательностях, образуя чертежи для каждого живого организма.
И эта система хранения информации невероятно плотная: один грамм ДНК способен
хранить до 215 петабайт (215 миллионов ГБ) данных.
Это делает его
очень привлекательным потенциальным решением для хранения огромных объемов
данных, которые современное общество производит ежедневно — все содержимое
Интернета может поместиться в обувной коробке, полной ДНК. И как будто это
хранилище было недостаточно плотным, исследователи нового исследования нашли
способ удвоить его.
Наряду с обычными
A, G, C и T команда добавила дополнительные семь «букв» в алфавит ДНК. Они
принимают форму химически модифицированных нуклеотидов, открывая более
разнообразные комбинации, которые позволяют хранить больше информации в том же
объеме физического пространства.
«Представьте себе английский алфавит», — говорит Касра Табатабаи, соавтор исследования. «Если бы было только четыре буквы, можно составить столько-то слов. Если бы был полный алфавит, можно создавать неограниченное количество комбинаций слов. То же самое и с ДНК. Вместо того, чтобы преобразовывать нули и единицы в A, G, C и T, мы можем преобразовать нули и единицы в A, G, C, T и семь новых букв в алфавите хранения».
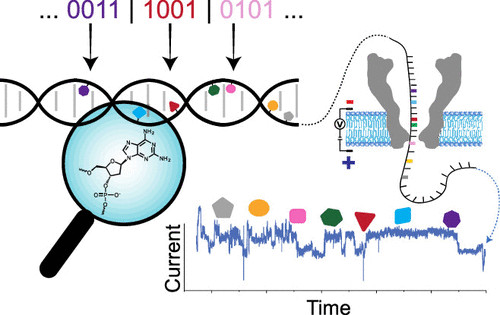
Конечно,
добавление дополнительных нуклеотидов означает, что существующие системы
обратного считывания данных не распознают их, поэтому команда также разработала
новую систему, которая может это делать. Нить ДНК проходит через нанопоры в
специально разработанном белке, который может обнаруживать отдельные единицы
независимо от того, являются ли они природными или синтетическими. Затем
алгоритмы машинного обучения декодируют информацию, хранящуюся внутри.
«Мы испробовали
77 различных комбинаций 11 нуклеотидов, и наш метод смог идеально
дифференцировать каждую из них», — сказал Чао Пан, соавтор исследования.
«Структура глубокого обучения как часть нашего метода идентификации различных
нуклеотидов является универсальной, что позволяет обобщать наш подход во многих
других приложениях».
В дополнение к
плотности новый метод также повышает скорость записи данных, что обычно
является довольно медленным процессом для ДНК. Эта система примерно вдвое
сократила время, необходимое для записи информации в ДНК.
Эта работа может
помочь сделать ДНК жизнеспособной системой хранения данных, хотя предстоит еще
много работы.
Исследование было
опубликовано в журнале Nano Letters.
Комментарии:

Обзор технологий стелс в военной авиации
Военная авиация играет решающую роль в современных конфликтах, и ее эффективность зависит от различных факторов, включая возможность избежать обнаружения и атаки противника.

Цветы: как они влияют на нашу жизнь и эмоции
Цветы играют особую роль в жизни каждого человека.

Техника Lenovo: надежность и долговечность при эксплуатации
Покупка технического устройства - это процесс, в котором важно учитывать различные нюансы, напрямую связанные с базовыми характеристиками приспособления и его функциональностью.

Лучшие модели наушников JBL: обзор и характеристики
JBL наушники широко известны высоким качеством звука и надёжностью, благодаря чему они завоевали доверие различных категорий пользователей — от меломанов до спортсменов.
«Квантовая суперхимия» впервые наблюдалась в лабораторных экспериментах
Ученые из Чикагского университета обнаружили первое свидетельство явления под названием «квантовая суперхимия». Давно предсказанный, но так и не подтвержденный, этот эффект может ускорить химические реакции, дать ученым больше контроля над ними и послужить основой для квантовых вычислений.

Умная ткань с покрытием из жидкого металла «заживает» при порезах и отталкивает бактерии
Наука продолжает развивать умные ткани, которые реагируют на изменения окружающей среды и предоставляют больше «услуг» своим владельцам.

Лазер обнаруживает и идентифицирует бактерий за считанные минуты
Чтобы увидеть, какой тип бактерий присутствуют в образце жидкости, необходимо выращивать бактериальные культуры в лаборатории в течение нескольких часов или даже дней. Новая лазерная техника работает всего за несколько минут.

Ультратонкое покрытие делает солнечные батареи самоочищающимися
Солнечные панели не могут эффективно работать когда грязные, но их регулярная очистка может занять много времени. Инженеры в Германии разработали ультратонкое покрытие, которое сделает солнечные панели и другие поверхности самоочищающимися.
